
MyBatis学习笔记
💧 💧 💧
SQL映射文件,延迟加载,日志,二级缓存的使用,一对一,一对多…
映射文件设置
一. 标签
1). SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
- cache – 给定命名空间的缓存配置。
- cache-ref – 其他命名空间缓存配置的引用。
- resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
二. 标签属性
- 一个参数时可以不写参数类型
- 输入参数如果是简单类型(8个基本类型+String) 是可以使用任何占位符,#{xxxx}
如果是对象类型,则必须是对象的属性 #{属性名},属性值需要严格区分大小写 - 输入参数parameterType 和 输出参数resultType ,在形式上都只能有一个
1 | <select id="唯一标识" paramterType="参数类型" reusltType="返回类型" resultMap="返回map映射" |
三. sql
- 用来定义可重用的sql代码段,可以包含在其他语句中
- 它可以被静态地(在加载参数)参数化,不同的属性值通过包含实力变化
1 | <!-- |
四. #和$区别
类型为简单类型(8个基本类型+String)
1). #{}、${}的区别
①#{任意值}
${value} ,其中的标识符只能是value
②#{}自动给String类型加上’’ (自动类型转换)
${} 原样输出,但是适合于 动态排序(动态字段)
2). #{}、${}的使用
- #和$区别一个转义一个不转义,等价于jdbc的statement和preparedStatement。
- #{key}:获取参数的值,预编译到SQL中。防止sql注入,安全。
- ${key}:获取参数的值,拼接到SQL中。原样输出,灵活。
- 一般使用#{},当使用原生jdbc不支持占位符的sql时使用${},如动态排序
order by,(动态字段)。
1 | <!-- 字符串替换 # $ --> |
五. resultType自动映射
输出参数resultType
1.简单类型(8个基本+String)
2.输出参数为实体对象类型
3.输出参数为实体对象类型的集合 :虽然输出类型为集合,但是resultType依然写集合的元素类型(resyltType=”Student”)
4.输出参数类型为HashMap
—HashMap本身是一个集合,可以存放多个元素,
—>结论:一个HashMap 对应一个学生的多个元素(多个属性)
1). autoMappingBehavior默认是PARTIAL,开启自动映射的功能。唯一的要求是结果集列名和javaBean属性名一致。
2). 如果autoMappingBehavior设置为null则会取消自动映射。
六. resultMap自定义映射
实现高级结果集映射
- id :用于完成主键值的映射
- result :用于完成普通列的映射
- association :一个复杂的类型关联;许多结果将包成这种类型(一对一)
- collection : 复杂类型的集(一对多)
多对多的本质就是一对多的变化
1). 多表查询association
①员工类1
2
3
4
5
6
7
8
9
10
11
12public class Emp {
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Double sal;
private Double comm;
private Dept dept;
//省略git/sit
}
②部门类1
2
3
4
5
6
7public class Dept {
private Integer deptno;
private String dname;
private String loc;
//省略git/sit
}
③sql映射文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31<!-- 将查询到的复杂数据映射到一个结果集中 -->
<resultMap type="Emp" id="empMapping">
<!--
分为主键id 和非主键 result
property:java类的属性名
column:数据库字段名
javaType:java类型,例"boolean"
jdbcType:数据库类型,例"INTEGER"
-->
<id property="empno" column="empno" />
<result property="ename" column="ename" />
<result property="job" column="job" />
<result property="mgr" column="mgr" />
<result property="hiredate" column="hiredate" />
<result property="sal" column="sal" />
<result property="comm" column="comm" />
<!--
association:定义对象的封装规则
column:根据数据库编号连接表
javaType:java自定义类型
-->
<association property="dept" javaType="Dept" column="deptno">
<id property="deptno" column="deptno"/>
<result property="dname" column="dname"/>
<result property="loc" column="loc"/>
</association>
</resultMap>
<select id="selectEmpByEmpno" parameterType="int" resultMap="empMapping">
select * from emp e left join dept d on d.deptno=e.deptno where empno= #{empno}
</select>
- 引用数据类型时需使用别名(全局配置文件中)
1 | <typeAliases> |
④在全局配置文件中设置autoMappingBehavior
1 | <settings> |
⑤将autoMappingBehavior的值改为FULL可将sql映射文件简写1
2
3
4
5
6
7
8 <resultMap type="Emp" id="empMapping">
<association property="dept" javaType="Dept" column="deptno">
</association>
</resultMap>
<select id="selectEmpByEmpno" parameterType="int" resultMap="empMapping">
select * from emp e left join dept d on d.deptno=e.deptno where empno= #{empno}
</select>
2). 分步查询association
POJO中的属性可能会是一个对象,我们可以使用联合查询,并以级联属性的方式封装对象.使用association标签定义对象的封装规则(一对一)
①sql映射文件
EmpMapper.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<mapper namespace="com.AAA.Text.dao.EmpMapper">
<!-- 将查询到的复杂数据映射到一个结果集中 -->
<resultMap type="Emp" id="empMapping">
<id property="empno" column="empno"/>
<!--
association:定义对象的封装规则
property:实体类中该属性的名称(需一致)
column:根据数据库中外键编号连接表
javaType:java自定义类型
一对一需要调用部门中的根据id查询方法
-->
<association property="dept" javaType="Dept" column="deptno" select="com.AAA.Text.dao.DeptMapper.selectDeptByDeptno">
</association>
</resultMap>
<select id="selectEmpByEmpno" parameterType="int" resultMap="empMapping">
select * from emp where empno= #{empno}
</select>
</mapper>DeptMapper.xml
1
2
3
4
5<mapper namespace="com.AAA.Text.dao.DeptMapper">
<select id="selectDeptByDeptno" parameterType="int" resultType="dept">
select * from dept where deptno = #{deptno}
</select>
</mapper>
②全局配置文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38<!-- 引入文件 -->
<properties resource="db.properties"/>
<!--
settings包含很多重要的设置项
setting:用来设置每个设置项
name:设置项名
value:设置项取值
-->
<settings>
<!-- 自动映射到相应驼峰形式的java属性名 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- 指定数据表字段和对象属性的映射方式 -->
<setting name="autoMappingBehavior" value="FULL"/>
</settings>
<!-- 设置别名 -->
<typeAliases>
<package name="com.AAA.Text.entity"/>
</typeAliases>
<!-- 设置连接数据库的环境 -->
<environments default="development">
<environment id="development">
<!-- 使用JDBC事务管理 -->
<transactionManager type="JDBC"/>
<!-- 数据库连接池 -->
<dataSource type="POOLED">
<!-- 配置数据库信息 -->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!-- 将我们写好的sql映射注册到全局配置文件中-->
<mappers>
<mapper resource="com/AAA/Text/dao/EmpMapper.xml"/>
<mapper resource="com/AAA/Text/dao/DeptMapper.xml"/>
</mappers>
- 在分步查询的基础上,可以使用延迟加载来提升查询的效率,只需要在全局的Settings中进行如下的配置:
1
2
3
4<!-- 开启延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 设置加载的数据是按需还是全部 -->
<setting name="aggressiveLazyLoading" value="false"/>
3).多表查询collection
①员工类1
2
3
4
5
6
7
8
9
10
11public class Emp {
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Double sal;
private Double comm;
private Integer deptno;
//省略git/sit
}
②部门类1
2
3
4
5
6
7public class Dept {
private Integer deptno;
private String dname;
private String loc;
private List<Emp> emps;
//省略git/sit
}
③sql映射文件1
2
3
4
5
6
7
8
9
10
11
12<mapper namespace="com.AAA.Text.dao.DeptMapper">
<resultMap type="Dept" id="deptemp">
<id property="deptno" column="deptno"></id>
<!-- 用ofType指定集合里面的类型 -->
<collection property="emps" ofType="emp">
</collection>
</resultMap>
<select id="selectByDeptno" resultMap="deptemp">
select * from dept d,emp e where d.deptno=e.deptno and d.deptno=#{vv}
</select>
</mapper>
④测试文件1
2
3
4
5
6public static void main(String[] args) {
// TODO Auto-generated method stub
DeptMapper mapper = MybatisUtil.getSession().getMapper(DeptMapper.class);
Dept dept = mapper.selectByDeptno(20);
System.out.println(dept);
}
4). 分步查询collection
POJO中的属性可能会是一个集合对象,我们可以使用联合查询,并以级联属性的方式封装对象.使用collection标签定义对象的封装规则(一对多)
①sql映射文件
EmpMapper.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<mapper namespace="com.AAA.Text.dao.EmpMapper">
<!-- 将查询到的复杂数据映射到一个结果集中 -->
<resultMap type="Emp" id="empMapping">
<id property="empno" column="empno"/>
<!--
association:定义对象的封装规则
property:实体类中该属性的名称(需一致)
select:调用查询所关联表的方法
column:根据数据库编号连接表
javaType:java自定义类型
-->
<association property="dept" javaType="Dept" column="deptno" select="com.AAA.Text.dao.DeptMapper.selectDeptByDeptno">
</association>
</resultMap>
<select id="selectEmpByEmpno" parameterType="int" resultMap="empMapping">
select * from emp where empno= #{empno}
</select>
<select id="selectEmpBydeptno" parameterType="int" resultMap="empMapping">
select * from emp where deptno= #{deptno}
</select>
</mapper>DeptMapper.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<mapper namespace="com.AAA.Text.dao.DeptMapper">
<!-- 将查询到的复杂数据映射到一个结果集中 -->
<resultMap type="Dept" id="deptMapping">
<id property="deptno" column="deptno"/>
<!--
collection:定义这个集合中元素的封装规则
property:实体类中关联的属性名(需一致)
ofType: 指定集合中元素的类型
column:数据库当前表编号
fetchType="lacy":表示使用延迟加载,(eager-立即加载)
select:找到连接表的查找外键的方法
-->
<collection property="emps" ofType="Emp" column="deptno" select="com.AAA.Text.dao.EmpMapper.selectEmpBydeptno"></collection>
</resultMap>
<select id="selectDeptByDeptno" parameterType="int" resultMap="deptMapping">
select * from dept where deptno = #{deptno}
</select>
</mapper>
②测试类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public static void main(String[] args) throws Exception {
//Mapper接口:获取Mapper接口的 代理实现类对象
EmpMapper em = MybatisUtil.getSession().getMapper(EmpMapper.class);
DeptMapper dm = MybatisUtil.getSession().getMapper(DeptMapper.class);
/*
* 在核心文件里要配置延迟加载和是否立即加载的setting配置
* 在映射文件里要使用reusltmap方式和一对多和多对一单表方式
* 需要引入两个jar包(asm.jar/cglib.jar)
* */
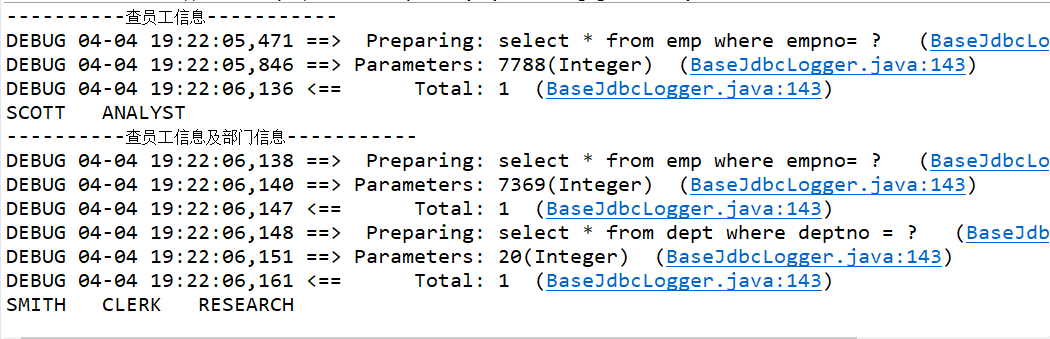
System.out.println("----------查根据员工编号查员工信息-----------");
Emp emp = em.selectEmpByEmpno(7788);
System.out.println(emp.getEname()+"\t"+emp.getJob());
System.out.println("----------查根据员工编号查员工信息及部门信息-----------");
Emp emp2 = em.selectEmpByEmpno(7369);
System.out.println(emp2.getEname()+"\t"+emp2.getJob()+"\t"+emp2.getDept().getDname());
System.out.println("----------查根据部门编号查询部门信息-----------");
Dept dept = dm.selectDeptByDeptno(20);
System.out.println(dept.getDeptno()+"\t"+dept.getDname());
System.out.println("----------查根据部门编号查询所有员工信息-----------");
Dept dept2 = dm.selectDeptByDeptno(20);
System.out.println(dept2.getDeptno()+"\t"+dept2.getDname()+"\t"+dept2.getEmps().size());
for(Emp emp3 : dept2.getEmps()){
System.out.println(emp3.getEname());
}
}
当使用延迟加载时,只会查询需要的表
5). 日志
①添加log4j.jar
②开启日志1
2
3
4<settings>
<!-- 开启日志,并指定使用的具体日志 -->
<setting name="logImpl" value="LOG4J"/>
</settings>
如果不指定也可以,Mybatis就会根据以下顺序 寻找日志
③编写日志文件log4j.properties1
2
3
4=DEBUG, stdout
=org.apache.log4j.ConsoleAppender
=org.apache.log4j.PatternLayout
=%5p [%t] - %m%n
日志级别:
如果设置为info,则只显示 info及以上级别的信息;
建议:在开发时设置debug,在运行时设置为info或以上。
④日志作用
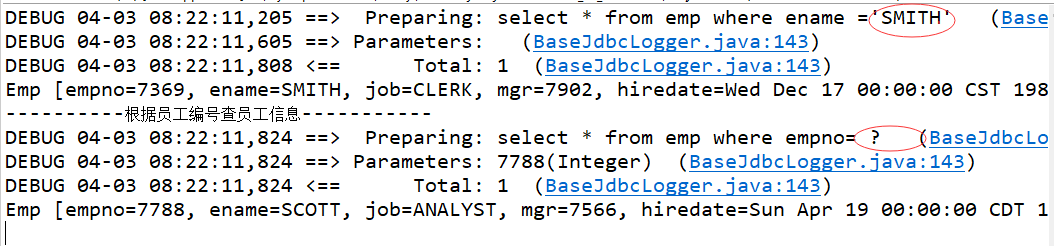
可以通过日志信息,相信的阅读mybatis执行情况( 观察mybatis实际执行sql语句 以及SQL中的参数 和返回结果)
6). 二级缓存
缓存使用原理:查询时,先从一级缓存(session)中查,一级缓存没有再找二级缓存(factory),二级缓存没有再找数据库,然后数据库将结果返回并添加到缓存中。
①全局配置文件
1 | <settings> |
②sql映射文件
1 | <!-- 声明开启二级缓存,只能在查询中使用 --> |
七. 扩展
1). 分步查询多列值的传递
如果分步查询时,需要传递给调用的查询中多个参数,则需要将多个参数封装成
Map来进行传递,语法如下: {k1=v1, k2=v2….}在所调用的查询方,取值时就要参考Map的取值方式,需要严格的按照封装map
时所用的key来取值.
2). association 或 collection的 fetchType属性
在
和 标签中都可以设置fetchType,指定本次查询是否要使用延迟加
载。默认为fetchType=”lazy” ,如果本次的查询不想使用延迟加载,则可设置为fetchType=”eager”.fetchType可以灵活的设置查询是否需要使用延迟加载,而不需要因为某个查询不想使用延迟加载
将全局的延迟加载设置关闭.

- 本文作者:
腾飞
- 本文链接:
https://www.tengfei.eu.org/article/c4c597c7.html
- 版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!